I've been developing the year-span histograms posted earlier. In these sketches, the series are again represented as single horizontal lines that correspond to their date spans. To address the problem of series overlapping each other, this sketch sorts and stacks the series into a single big, non-overlapping heap. The method is fairly simple. First, sort all the series by their span, longest to shortest (this involved learning to implement Java's Comparable function). Then, place the series in the stack, longest to shortest, bottom to top. A simple 2D array is used to keep track of series positions and check collisions; if a collision is found, simply try the next row up and repeat until a space is found.
The result is almost, but not quite, a histogram (because the packing isn't perfect - there are some gaps). Unlike the earlier sketches though, it visualises the total number of series spanning a given year, rather than just the commencing year; this seems a more generally useful feature to visualise. It's interesting to note though that some of the features obvious in the commencing year histogram are less clear here - notably the spikes around Federation and the Wars.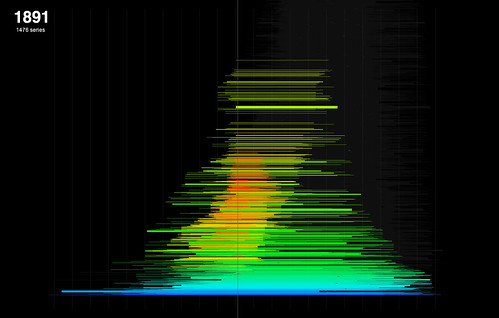
The real payoff for the stacking is that now we have a potential interface to the entire collection, at series level. Adding interaction makes it easy to browse the visualisation by year, showing the relation between series in that year and the total collection. Sheer scale is still a problem. This "heap" is more than 10,000 series high - too big to usefully show every series even at one pixel each. Interaction allows zooming and panning (above), which helps. Next, I'd like to be able to filter the heap down to a more manageable size, to a point where this can become the interface to browse through individual series.
One of the obvious limits of the first histogram is that series - or more specifically series contents, here - have an end date as well a start date; and the date span of a series is far more informative than the start date alone. So here's a first attempt at introducing date span into the visualisation. It's really a minimal tweak of the previous sketch; instead of drawing a vertical line with the histogram count (number of series commencing at a given date), I draw a stack of translucent horizontal lines from start to end year. I've also increased the scale here, so that each series line is a single pixel high; and the grid lines are now at 10 rather than 25 year intervals. Click for the full res image. This adds a lot of visual detail, but it also obscures quite a lot. The drawing order is essentially arbitrary (it's the order of series records in the dataset as provided) and there's no collision checking, so all the lines are just overlaying each other. We can get a vague sense of the range of date spans from the top of the "spike" years, where a single stack of series lines is more clearly visible; and we can see that although the series start dates drop off sharply after 1960 (as shown in the first histogram), many series have end dates in the last 20 years.
This adds a lot of visual detail, but it also obscures quite a lot. The drawing order is essentially arbitrary (it's the order of series records in the dataset as provided) and there's no collision checking, so all the lines are just overlaying each other. We can get a vague sense of the range of date spans from the top of the "spike" years, where a single stack of series lines is more clearly visible; and we can see that although the series start dates drop off sharply after 1960 (as shown in the first histogram), many series have end dates in the last 20 years. In another quick tweak I added colour to the graph, in an attempt to pull out some of what's hidden here. By simply mapping the duration of a series (in years) to the line's hue, we can see more about the overall distribution of durations. It seems, for example, that there are a small subset of series that commence around 1900 or earlier, with very long durations. It also seems that most of the series around WWII had quite short date spans - plausible enough. So we can see a bit more here but the overdrawing problem is still significant. My next step will be to address this, perhaps by managing the drawing / stacking order to reduce overdrawing; or adding some interaction that will allow date-based highlighting of series stacks. Also in my plans is a way to stack series without any overlaps at all; a kind of packing problem. Plenty to do...
In another quick tweak I added colour to the graph, in an attempt to pull out some of what's hidden here. By simply mapping the duration of a series (in years) to the line's hue, we can see more about the overall distribution of durations. It seems, for example, that there are a small subset of series that commence around 1900 or earlier, with very long durations. It also seems that most of the series around WWII had quite short date spans - plausible enough. So we can see a bit more here but the overdrawing problem is still significant. My next step will be to address this, perhaps by managing the drawing / stacking order to reduce overdrawing; or adding some interaction that will allow date-based highlighting of series stacks. Also in my plans is a way to stack series without any overlaps at all; a kind of packing problem. Plenty to do...
After some admin delays, I collected the data from the Archives yesterday, and have been digging in with some excitement. The data consists of three big XML files, totalling around 300Mb; initially I have been looking at the largest of these datasets (180Mb), which records the 27000+ series in the Archives collection.
Initial data-munging presented some challenges, as expected; many of the records contained HTML in plain text wrapped inside the XML. Archives staff had warned me about this and I'd blithely replied that it would be fine, and the more data the better. Of course the first thing that happened as I attempted to parse the XML with Processing, was that the HTML broke the parser. So step one was to make a copy of the dataset without the HTML; a quick grep tutorial later and I was able to use Textwrangler to automate the process of stripping it out, reducing the file size along the way to about 50Mb.
After that the process of getting the data in to Processing has been straightforward, and I'm impressed with its ability to ingest a large lump of XML without complaint. As a sort of "hello world" visualisation I decided to make a simple histogram of the entire series dataset by date; specifically, the start date of the contents of each series (click the image to see it without the nasty scaling artefacts, at full resolution). The x axis is year, with a range from 1800 to 2000; the y axis is the number of series with that start date; it's unlabelled here but the maximum value (in 1950) is about 960. Already you can get a sense of the shape of the collection from this image; there are spikes at 1901 and 1914 that correspond, I'd guess, to Federation and World War I; and the next spike is, of course, 1939. One question I can't answer at the moment is why there is such a dramatic drop in the number of series commencing after 1960 - perhaps a change in recordkeeping or the archival process itself? Any thoughts?
