After being completely buried under end-of-year admin for a few weeks, it's great to be back to work on this project. I've been working on plumbing in the latest dataset from the Archives, which has doubled in size to around 57,500 series. In an attempt to create a browsable overview of the whole collection, I have been developing the earlier grid sketches, feeding in more data, and extra parameters. Also new in this dataset are two interesting features of archival series: items - number of catalogued items in the series - and shelf metres - the amount of physical space the series occupies. In this interactive browser, you can navigate around the whole collection, and switch between modes that display these parameters.
A brief explanation. Like the earier grid, series are sorted by start date (still contents start date, rather than accumulation, for the moment) then simply layed out from top left to bottom right. In this version I've added some year labels on the Y axis, which show the distribution of the series through time. Hue is mapped directly to date span: red series have a short date span, blue have a long span. The four modes in this interactive change the mapping for brightness. In the default display brightness is mapped to items (I); M switches the brightness key to shelf metres; P shows items per shelf metre; and S switches the brightness key off (showing span/hue only).
Both these new parameters have a wide range and a very uneven distribution, and as you can see in the visualisation there are many series with zero items and/or zero metres. In fact around 30000 series (over half this collection) have zero digitised items; while around 2600 have between 100 and 1000 items, and 13 have more than 10000 items. Around 20000 series have zero shelf metres, around the same number have 0.1-1m, around 10000 have between 1m and 10m, and the rest have more than 10m - with a couple of dozen series with more than 1km of shelf space! It's important to remember, as Archives staff have mentioned to me, that items here refers to digitised items. Series with zero listed items aren't empty, they just haven't been digitised. Similarly I suspect that a value of zero shelf metres suggests that the data doesn't exist. Even if it can't be taken at face value, items is an interesting metric because the Archives digitises records largely on the basis of demand from users; so a series that is frequently requested is more likely to be digitised. Items, then, is partly a measure of how interesting a series is, to Archives users.
The items view of the grid allows us to see, for example, that there are more digitised items in series commencing in the 20s and 30s, than there are in series commencing in the 60s and 70s. We can also see a dense band of well-digitised series from the late 90s onwards. I don't know, but I'd suspect that these are "born digital" records - no digitisation required. The most striking feature of the items graph is the narrow red streaks around 1950: these are Displaced Persons records from 1948-52, each series corresponding to a single incoming ship (above). These records show up here because they are well digitised (interesting) but also because there are many sequential series forming visual groups. There are other pockets of "interestingness", but they are less obvious. This reveals one drawback of this grid layout, which is that related series are not necessarily grouped together. I'm hoping to address this when I start looking at agencies, functions, and links between series.
A few technical notes. After running into problems storing data in plain text, I changed the code to read the source XML in, pick out certain fields or elements, and write the data back out as XML. I used Christian Riekoff's ProXML library for Processing, which makes the file writing part very easy (Processing's built-in XML functions don't include a file writer). This worked well, except when it came to exporting web applets, which just refused to load. Rummaging around in the console log, and turning on Java's debugging tools (thanks Sam) showed that the applet was running out of memory while trying to load the XML - admittedly a fairly hefty 27Mb uncompressed. So for the web version at least, I have reverted to storing the data as plain text, which immediately reduced file size and loading time by a factor of 4, and solved the applet problem. Since then Dan and Toxi have suggested alternative ways of handling the XML, such as SAX, which streams the data in and generates events on the fly, rather than loading the whole XML tree into memory before parsing it. I'll be looking into that for any serious web implementation of this stuff.
Finally, with almost 60000 objects on the screen, this visualisation raises some basic computation and design issues. Even using accelerated OpenGL, this is a tall order; I found I was getting around one frame per second on a moderately powerful computer. I have solved the issue here with a simple workaround (thanks Geoff for this one) - pre-render an image of the grid, then overlay the interactive elements. Performance issue solved. But there are some limitations: this approach means the grid layout is fixed. It's a significant move away from a truly "dynamic" visualisation, where all the elements are drawn on the fly. For visualisations at this scale, I don't think there's any other way, but as the design develops I'll be trying to push back towards the live, dynamic approach, as the dataset permits.
So, it's no Wordle, but it's my first text cloud. This visualises the 250 most common words in the titles of each series in the initial dataset. It's also the first time I've mined the titles for data, and another step in the process of feeling out the attributes of this dataset. I've excluded a few "stop" words ("and","with","the","for") and anything with less than three characters, but otherwise this is a raw representation of the titles.
It shows first of all that the most frequently occuring terms in series titles are either generic descriptors ("files", "correspondence") or metadata, referring to the organisation or structure of the series, rather than its content ("alphabetical", "prefix", "single"). But then after the top twenty or so words, there's a large number of more descriptive terms. The difference in scale between these layers is significant; for example "series" and "files" occur in around 10,000 series titles (about a third of all series), whereas "drawings" occurs in around 800 series, and "HMAS", "Papua" and "Lighthouse" all occur in around 200 series. Some odd features show up as well, for example "Yokohama" and "specie"; turns out there are a large number of series consisting of records from the Yokohama Specie Bank, a Japanese bank involved in trade with China and Australia around the mid-C20th - it gets a mention in this 1940 telegram from Menzies to the High Commissioner in London. I wonder how the records ended up in the Archives?
Next, to try integrating text clouds as interfaces / overlays for the previous visualisations.
I've been considering how to develop the stack histograms, but meantime decided to quickly trial a completely different approach to visualising the Series dataset. I don't want to get carried away with one metaphor / approach, when there may be others worth exploring. So, in this visualisation some 27000 series are layed out in a simple grid. Series are ordered by (contents) start date, and sequenced left to right, top to bottom. As in the last histograms, date span is mapped to hue, so long spans are blue, short spans are red. I've been having some weird issues with web applets so far, but this one seems to work (without OpenGL), so there's also an interactive version to play with.
This layout has a number of advantages over the stack approach. The primary one is visual density. This layout makes it possible to see all the series, in a single visual field. In the examples here the grid is 200 columns wide and around 135 rows high; each series is a 4 x 4 pixel square. Even allowing for 40000 series in an expanded dataset (more of which soon), this scale is functional. A related advantage is browsability. In the interactive version of this sketch, we can simply mouse over series to see their details; a usable, if still unstructured way to browse the collection.
The grid throws away the emergent histogram-form of the stack approach. However many related structures are still apparent: for example the pattern of long-span series having early start dates is clear; and the interactive version also reveals the date distribution; the reddish band in the middle of the grid is the wave of short series around WWII. One thing on the list to try is add a date key to the vertical axis. This would effectively show the same thing as the tall peaks of the original histogram: the relative numbers of series commencing over time. The grid simply structures space according to the data elements (the series), so that the relation of date to visual space becomes nonlinear; but the relationship is still there and easily revealed.
Next on the list of things to try is a word-frequency visualisation based on series titles. This should provide a way to browse the grid more effectively; after that, I need to get to work on a new, expanded dataset with more series, but also useful quantitative measures like shelf space and digitised items, for each series. Then, more layers of structure and browsability: relationships between series, agency and function.
I've been developing the year-span histograms posted earlier. In these sketches, the series are again represented as single horizontal lines that correspond to their date spans. To address the problem of series overlapping each other, this sketch sorts and stacks the series into a single big, non-overlapping heap. The method is fairly simple. First, sort all the series by their span, longest to shortest (this involved learning to implement Java's Comparable function). Then, place the series in the stack, longest to shortest, bottom to top. A simple 2D array is used to keep track of series positions and check collisions; if a collision is found, simply try the next row up and repeat until a space is found.
The result is almost, but not quite, a histogram (because the packing isn't perfect - there are some gaps). Unlike the earlier sketches though, it visualises the total number of series spanning a given year, rather than just the commencing year; this seems a more generally useful feature to visualise. It's interesting to note though that some of the features obvious in the commencing year histogram are less clear here - notably the spikes around Federation and the Wars.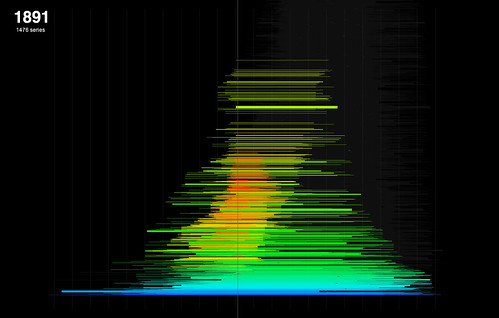
The real payoff for the stacking is that now we have a potential interface to the entire collection, at series level. Adding interaction makes it easy to browse the visualisation by year, showing the relation between series in that year and the total collection. Sheer scale is still a problem. This "heap" is more than 10,000 series high - too big to usefully show every series even at one pixel each. Interaction allows zooming and panning (above), which helps. Next, I'd like to be able to filter the heap down to a more manageable size, to a point where this can become the interface to browse through individual series.
One of the obvious limits of the first histogram is that series - or more specifically series contents, here - have an end date as well a start date; and the date span of a series is far more informative than the start date alone. So here's a first attempt at introducing date span into the visualisation. It's really a minimal tweak of the previous sketch; instead of drawing a vertical line with the histogram count (number of series commencing at a given date), I draw a stack of translucent horizontal lines from start to end year. I've also increased the scale here, so that each series line is a single pixel high; and the grid lines are now at 10 rather than 25 year intervals. Click for the full res image. This adds a lot of visual detail, but it also obscures quite a lot. The drawing order is essentially arbitrary (it's the order of series records in the dataset as provided) and there's no collision checking, so all the lines are just overlaying each other. We can get a vague sense of the range of date spans from the top of the "spike" years, where a single stack of series lines is more clearly visible; and we can see that although the series start dates drop off sharply after 1960 (as shown in the first histogram), many series have end dates in the last 20 years.
This adds a lot of visual detail, but it also obscures quite a lot. The drawing order is essentially arbitrary (it's the order of series records in the dataset as provided) and there's no collision checking, so all the lines are just overlaying each other. We can get a vague sense of the range of date spans from the top of the "spike" years, where a single stack of series lines is more clearly visible; and we can see that although the series start dates drop off sharply after 1960 (as shown in the first histogram), many series have end dates in the last 20 years. In another quick tweak I added colour to the graph, in an attempt to pull out some of what's hidden here. By simply mapping the duration of a series (in years) to the line's hue, we can see more about the overall distribution of durations. It seems, for example, that there are a small subset of series that commence around 1900 or earlier, with very long durations. It also seems that most of the series around WWII had quite short date spans - plausible enough. So we can see a bit more here but the overdrawing problem is still significant. My next step will be to address this, perhaps by managing the drawing / stacking order to reduce overdrawing; or adding some interaction that will allow date-based highlighting of series stacks. Also in my plans is a way to stack series without any overlaps at all; a kind of packing problem. Plenty to do...
In another quick tweak I added colour to the graph, in an attempt to pull out some of what's hidden here. By simply mapping the duration of a series (in years) to the line's hue, we can see more about the overall distribution of durations. It seems, for example, that there are a small subset of series that commence around 1900 or earlier, with very long durations. It also seems that most of the series around WWII had quite short date spans - plausible enough. So we can see a bit more here but the overdrawing problem is still significant. My next step will be to address this, perhaps by managing the drawing / stacking order to reduce overdrawing; or adding some interaction that will allow date-based highlighting of series stacks. Also in my plans is a way to stack series without any overlaps at all; a kind of packing problem. Plenty to do...
After some admin delays, I collected the data from the Archives yesterday, and have been digging in with some excitement. The data consists of three big XML files, totalling around 300Mb; initially I have been looking at the largest of these datasets (180Mb), which records the 27000+ series in the Archives collection.
Initial data-munging presented some challenges, as expected; many of the records contained HTML in plain text wrapped inside the XML. Archives staff had warned me about this and I'd blithely replied that it would be fine, and the more data the better. Of course the first thing that happened as I attempted to parse the XML with Processing, was that the HTML broke the parser. So step one was to make a copy of the dataset without the HTML; a quick grep tutorial later and I was able to use Textwrangler to automate the process of stripping it out, reducing the file size along the way to about 50Mb.
After that the process of getting the data in to Processing has been straightforward, and I'm impressed with its ability to ingest a large lump of XML without complaint. As a sort of "hello world" visualisation I decided to make a simple histogram of the entire series dataset by date; specifically, the start date of the contents of each series (click the image to see it without the nasty scaling artefacts, at full resolution). The x axis is year, with a range from 1800 to 2000; the y axis is the number of series with that start date; it's unlabelled here but the maximum value (in 1950) is about 960. Already you can get a sense of the shape of the collection from this image; there are spikes at 1901 and 1914 that correspond, I'd guess, to Federation and World War I; and the next spike is, of course, 1939. One question I can't answer at the moment is why there is such a dramatic drop in the number of series commencing after 1960 - perhaps a change in recordkeeping or the archival process itself? Any thoughts?
So after signing the contracts at the Archives thismorning, I can declare this Day One, and the project has officially started. The contract revealed some good stuff. The project will focus, as proposed, on two levels, visualising high level structures in the entire collection (series, agencies and functions); and within an individual series. Even better, that individual series will be A1, a huge collection dating from Federation up to WWII - more than 20,000 records that occupy over 450 metres of shelf space! I understand that this series is also very highly digitised - which raises the prospect of working with not only the catalogue data, but the digitised records themselves.
Can't wait to get my hands on the data; I'll be meeting with the Archives again soon to discuss starting points, data formats, and so on.
Meantime, welcome to the brand new project blog. Your comments and thoughts are always welcome - for now I'm especially interested in related work in the visualisation of cultural datasets and digital archives. I'll be posting some of my own research in those areas soon, but if you have any pointers, send them along. Here's a short outline of the project, for starters.
This outline, presented to the Archives as a refinement of the original proposal, summarises the context, aims and outcomes of the project.
As archives are increasingly digitised, so their collections become available as rich, and very large, datasets. Individual records in these datasets are readily accessible through search interfaces, such as those the Archives already provides. However it is more difficult to gain any wider sense of these cultural datasets, due to their sheer scale. Conventional text-based displays are unable to offer us any overall impression of the millions of items contained in modern collections such as the National Archives. Searching the collection is something like wandering through narrow paths in a forest: what we need is a map.
This proposal is to research and develop techniques for visualising, or mapping, archival collections in a way that supports their management, administration and use. The specific aim is to develop techniques for revealing context: the patterns, high-level structures and connections
between items in a collection.
The practical outcomes of the project will be prototype interactive, browsable maps of the National Archives collection that apply these techniques at different structural levels:
- A map of the whole collection, at Series level, will show the "big picture": the size, scope and historical distribution of different series, the relations between series, and their corresponding Agencies and functions.
- A more detailed map will focus, as a test case, on a single series (A1), accumulating data from individual records to reveal the distinctive "shape" of that series.
prominent American researchers have recently announced a broadly related project. This project is highly innovative; by supporting it, the Archives would take a leading position in the field. The project would be extensively documented and well disseminated, drawing an international audience.
Outcomes
- A prototype browsable map showing the structure of the whole National Archives collection at a Series level, including the relationships between Series, collecting and controlling Agencies, and functions.
- A prototype map of a single series, linking to and contextualising individual items in the series.
- A set of sketches: static and dynamic visualisations that demonstrate a range of different approaches.
- A set of techniques and approaches for creating interactive maps of archival datasets. These will be applicable across the archives sector, and among other institutions dealing with digital collections.
- Documentation and dissemination of the project to an international audience.
